Documentation Index
Fetch the complete documentation index at: https://docs.redpill.ai/llms.txt
Use this file to discover all available pages before exploring further.
What is Confidential AI?
Confidential AI refers to AI models that run entirely inside Trusted Execution Environments (TEE), providing end-to-end privacy from input to output. Unlike regular models where only the gateway is TEE-protected, confidential AI models run the entire inference process inside secure enclaves.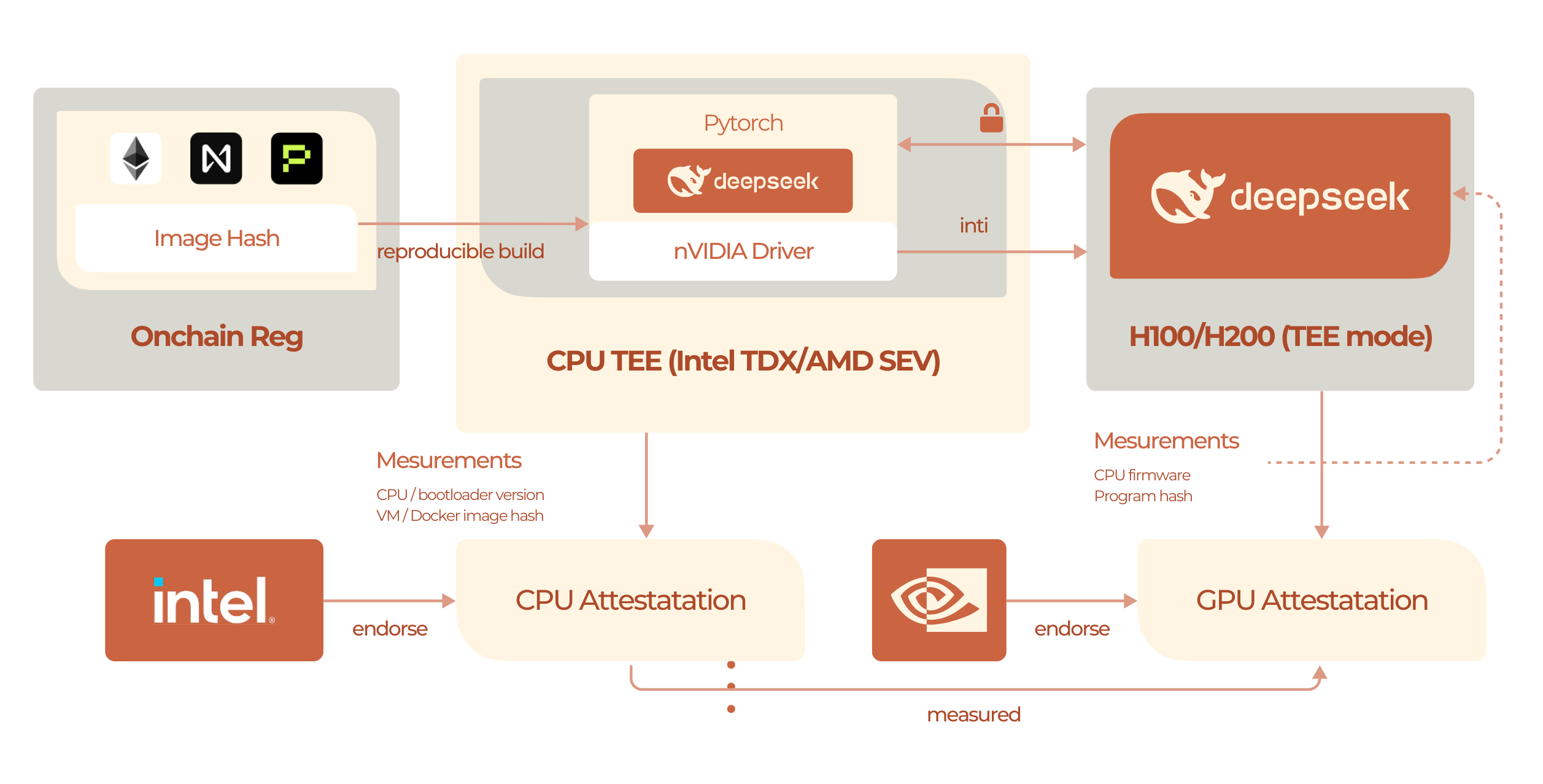
RedPill’s Two-Layer TEE Protection
RedPill offers dual privacy protection:Layer 1: TEE-Protected Gateway (All Models)
- ✅ Applies to all 50+ API models
- ✅ Request processing in TEE
- ✅ Response handling in TEE
- ✅ No additional cost
Layer 2: TEE-Protected Inference (GPU TEE Models)
- ✅ Model weights in GPU TEE
- ✅ Inference computation in TEE
- ✅ Complete end-to-end protection
- ✅ Cryptographic attestation
26 TEE Model Entries
Plus compatibility aliases
GPU TEE
NVIDIA H100/H200 secure enclaves
4 Providers
Phala, Tinfoil, Near AI, Chutes
Verifiable
Cryptographic attestation
GPU TEE Providers
RedPill offers 26 priced GPU TEE model entries across 4 GPU TEE providers. These are examples; use All Confidential AI Models orGET /v1/models for the live catalog.
Chutes
| Model | Parameters | Context | Use Case |
|---|---|---|---|
z-ai/glm-5.1 | Large | 203K | Systems engineering |
moonshotai/kimi-k2.6 | Large (MoE) | 262K | Visual coding |
qwen/qwen3.5-397b-a17b | 397B (MoE) | 262K | High-quality reasoning |
qwen/qwen3-coder-next | Large | 262K | Code generation |
deepseek/deepseek-v3.2 | 685B (MoE) | 164K | Latest DeepSeek |
Near AI
| Model | Parameters | Context | Use Case |
|---|---|---|---|
z-ai/glm-5 | Large | 203K | Systems engineering |
deepseek/deepseek-chat-v3.1 | 671B (MoE) | 164K | Hybrid reasoning |
openai/gpt-oss-120b | 117B (MoE) | 131K | OpenAI open-weight |
qwen/qwen3-30b-a3b-instruct-2507 | 30B (MoE) | 262K | General purpose |
z-ai/glm-4.7 | 130B | 131K | Bilingual (CN/EN) |
Phala Network
| Model | Parameters | Context | Use Case |
|---|---|---|---|
phala/qwen3.5-27b | 27B | 262K | General purpose |
phala/qwen3-vl-30b-a3b-instruct | 30B (MoE) | 128K | Vision + language |
qwen/qwen3-embedding-8b | 8B | 32K | Embeddings |
phala/gemma-3-27b-it | 27B | 53K | Multilingual |
phala/gpt-oss-20b | 21B (MoE) | 131K | Efficient inference |
Tinfoil (4 models)
| Model | Parameters | Context | Use Case |
|---|---|---|---|
qwen/qwen3-coder-480b-a35b-instruct | 480B (MoE) | 262K | Code generation |
moonshotai/kimi-k2-thinking | 1T (MoE) | 262K | Agentic reasoning |
deepseek/deepseek-r1-0528 | 685B (MoE) | 163K | Reasoning model |
meta-llama/llama-3.3-70b-instruct | 70B | 131K | General purpose |
All TEE Model Details
Explore all GPU TEE models →
How It Works
1. Model Loading in TEE
Model weights are decrypted only inside the GPU TEE.2. Request Processing
All pink nodes are TEE-protected - your data never leaves hardware security.3. Cryptographic Attestation
Every request generates verifiable proof:- GPU TEE measurements - Proves genuine NVIDIA H100 TEE
- Model hash - Verifies exact model version
- Code hash - Confirms inference code integrity
- Cryptographic signature - Signed by TEE hardware
Verify Attestation
Learn how to verify TEE proofs →
Privacy Guarantees
What CANNOT Be Accessed
Even with full system access, nobody can see:| Data Type | Accessible? | Protection |
|---|---|---|
| Your prompts | ❌ No | GPU TEE encrypted |
| Model responses | ❌ No | GPU TEE encrypted |
| Model weights | ❌ No | Encrypted at rest & in-use |
| Intermediate activations | ❌ No | GPU TEE memory isolation |
| Gradients (fine-tuning) | ❌ No | TEE-protected |
Trust Model
You must trust:- NVIDIA GPU vendor - H100/H200 TEE correctness
- Phala Network - Model deployment integrity
- Open source code - Auditable on GitHub
- ❌ RedPill operators
- ❌ Cloud provider (AWS, GCP, Azure)
- ❌ System administrators
- ❌ Other users on same hardware
Performance
Near-Native Speed
GPU TEE adds minimal overhead:| Metric | Native | TEE Mode | Overhead |
|---|---|---|---|
| Throughput | 100 tok/s | 99 tok/s | ~1% |
| Latency | 50ms | 51ms | ~2% |
| TFLOPS | 1979 | 1959 | ~1% |
Benchmark Results
See detailed performance benchmarks →
Use Cases
Healthcare
Process patient data with HIPAA compliance
Financial Services
Analyze confidential financial data
Legal
Handle privileged communications
Enterprise AI
Protect trade secrets and IP
Government
Classified data processing
Research
Sensitive research data analysis
Example Usage
vs Regular Models
| Feature | Regular Models | Confidential AI Models |
|---|---|---|
| Gateway TEE | ✅ Yes | ✅ Yes |
| Inference TEE | ❌ No | ✅ Yes |
| Model in TEE | ❌ No | ✅ Yes |
| End-to-end TEE | ❌ No | ✅ Yes |
| Attestation | ✅ Gateway only | ✅ Full stack |
| Model count | 50+ | 26 priced GPU TEE entries |
| Price | Provider pricing | Competitive |
Integration with Phala Network
RedPill’s confidential AI is powered by Phala Network, pioneers in:- GPU TEE - First GPU-based confidential computing
- Verifiable AI - Cryptographic proof of execution
- dstack - Open source TEE infrastructure
- Decentralized - Distributed trust model
Phala Documentation
Learn more about Phala’s TEE technology →
Compliance
Confidential AI helps meet regulatory requirements:- HIPAA - Healthcare data protection
- GDPR - European data privacy
- CCPA - California privacy law
- SOC 2 - Security controls
- ISO 27001 - Information security
- FedRAMP - US government (in progress)
FAQs
What's the difference between gateway TEE and confidential AI?
What's the difference between gateway TEE and confidential AI?
- Gateway TEE: Protects request routing (all 50+ API models)
- Confidential AI: Protects entire inference (Phala, Tinfoil, Near AI, Chutes models)
Are Phala models slower?
Are Phala models slower?
No! TEE mode runs at 99% of native speed. Performance impact is minimal.
Can I fine-tune Phala models?
Can I fine-tune Phala models?
Custom fine-tuning is available for enterprise customers. Contact sales@redpill.ai
How do I verify TEE execution?
How do I verify TEE execution?
Use the attestation API to get cryptographic proof. See Attestation Guide.
Which model should I choose?
Which model should I choose?
- Best quality:
z-ai/glm-5- Systems engineering flagship - OpenAI-compatible:
openai/gpt-oss-120b(117B MoE) - Reasoning:
deepseek/deepseek-r1-0528(685B MoE, Tinfoil) - Vision + language:
phala/qwen3-vl-30b-a3b-instruct(30B MoE) - Budget-friendly:
phala/qwen-2.5-7b-instruct(7B) - Lowest cost:
xiaomi/mimo-v2-flash($0.10/M input, Chutes)
Can I add custom Phala models?
Can I add custom Phala models?
Yes! Enterprise customers can deploy custom models in GPU TEE. Contact sales@redpill.ai
Next Steps
Phala Models
Explore all GPU TEE models
Attestation
Verify TEE execution
Verification
Signature verification guide
Get Started
Start using confidential AI